
Bayesian-Crowd-Counting
1 论文解读
ICCV19 (Oral)|基于贝叶斯损失函数的人群计数 - 知乎


拒绝 高斯热图 作为假gt | Bayesian Loss for Crowd Count Estimation with Point Supervision - 知乎 (zhihu.com)
先验 vs likelyhood vs 后验
- (先验)一个是 已知第n个人在图上, 其出现在点Xm的概率:以label为中心做二维高斯分布,此图称为先验概率图,即第n个人出现在各个点处的概率。
- (likehood)一个是 已知点Xm有人, 他是第n个人的概率:神经网络的输出就是概率密度图,估计出图中这个点有人的概率大小。
- (后验)一个是 在点Xm能看到第n个人的概率。prior服从均匀分布,P(y_1), P(y_2) … P(y_N) 全相等.即路人1号到n号出现在图上的概率相同 (戏份一样)
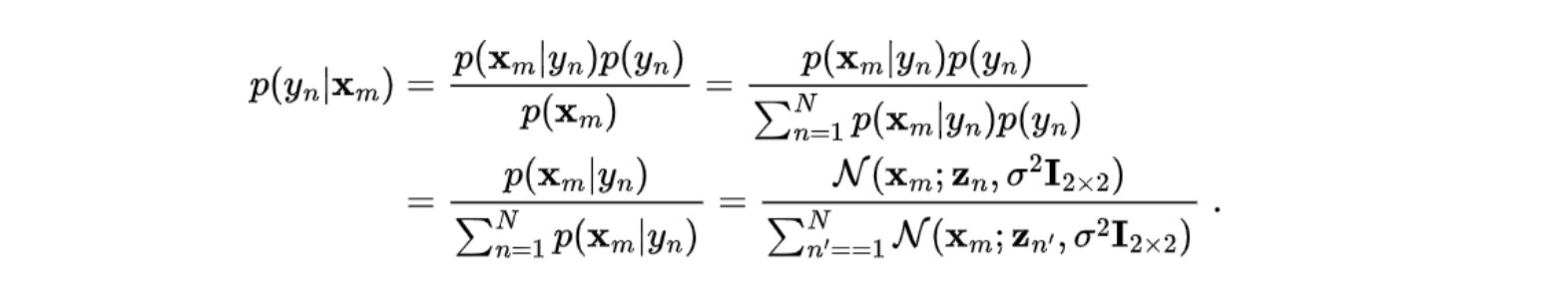
(整幅图上)路人n出现的数学期望:
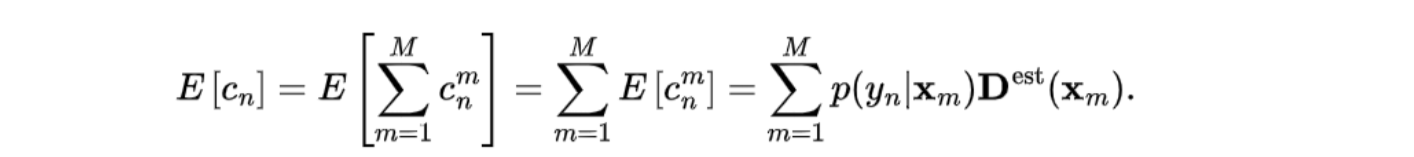
Bayesian loss
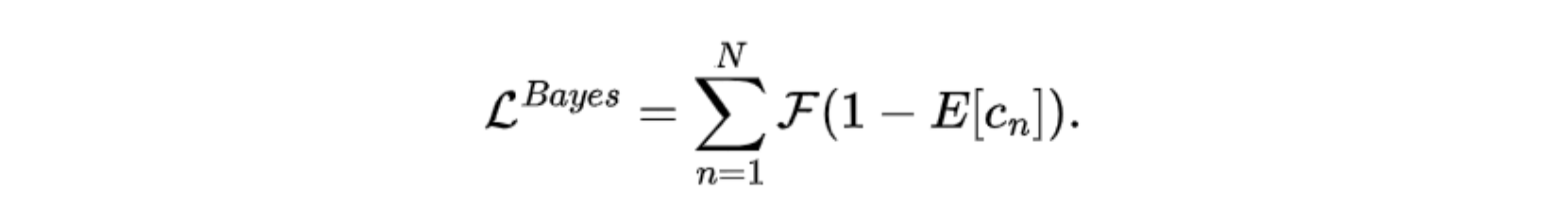
背景视为类别0,”吸收”零头概率
痛点:最终输出的heatmap上,背景区域的概率值不为0。网络输出的heatmap,背景区域可能有些非0。后验概率mask(用高斯分布表示),在很远处必然还大于0。
利用背景哑元,我们可以“吸收”远离人群的背景区域像素的“贡献”
背景哑元:把背景的某处,当作中心
增强的贝叶斯损失函数 Bayesian Loss+
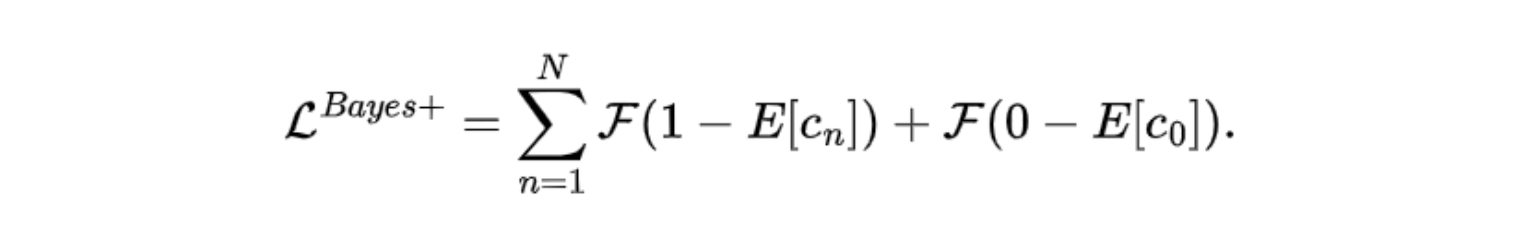
图上总人数C
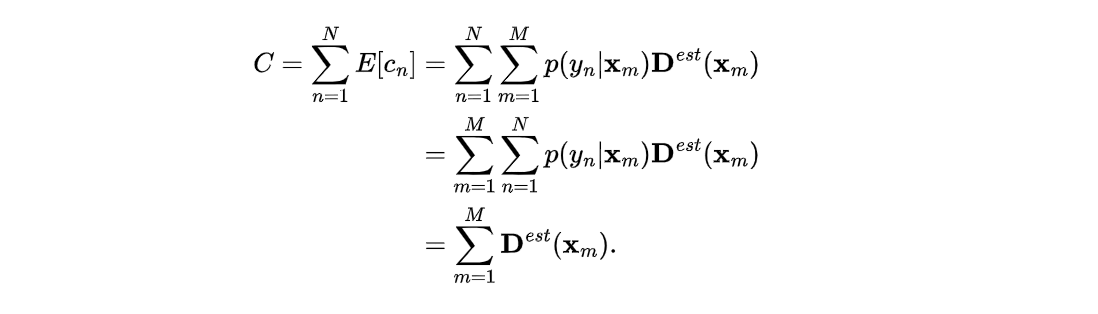
2 数据集
2.1 🌻数据集下载
服务器端开启多线程加速下载
aria2c --check-certificate=false -x 10 -k 1M -o /tmp/UCF-QNRF_ECCV18.zip https://www.crcv.ucf.edu/data/ucf-qnrf/UCF-QNRF_ECCV18.zip
2.2 🌵数据集介绍
从社会政治和安全的角度来看,在密集的人群场景中自动计数和定位具有重要意义。人群聚集在世界各地,在各种情况下,计算参与者人数通常是组织者和执法机构关注的重要问题。

UCF-QNRF数据集是一个,由弗罗里达大学在2018年发布。该数据集在格式和内容上具有以下特点:
- 图像数量:UCF-QNRF数据集共包含1535张高清大图,这些图像均为真实场景下的户外图像,具有极高的分辨率(如2013*2902),适用于训练需要高分辨率输入的模型。
- 图像分类:数据集被分为训练集和测试集两部分,其中训练集包含1201张图像,测试集包含334张图像。这种划分方式有助于在训练过程中评估模型的性能,并在最终测试阶段验证模型的泛化能力。
- 标注信息:每张图像都附有详细的标注信息,这些信息通常以MAT文件的形式存储。标注内容包括了图像中每个人的头部位置坐标(如[y0, x0]),用于计算图像中的人群密度和生成人群密度图。此外,标注还可能包括其他信息,如人群密度等级、场景类别等。
- 场景多样性:UCF-QNRF数据集包含了多种场景、多个视角、多种光线及密度变化的大规模已标注人体。这些图像涵盖了建筑、植被、天空和道路等世界各地的户外真实场景,对于研究不同地区人群密度具有重要意义。同时,数据集中的图像在人群密度、光照条件、拍摄角度等方面具有较大的变化范围,有助于训练出更加鲁棒和泛化能力更强的模型。
综上所述,UCF-QNRF数据集在格式和内容上都具有较高的规范性和丰富性。它提供了大量高清大图以及详细的标注信息,为训练和评估大规模人群密集计数模型提供了有力的支持。同时,数据集的多样性和复杂性也为模型的泛化能力和鲁棒性提出了更高的要求。
2.3 ☘️人口密度图生成
人口密度图生成过程总共两部分
- 利用坐标数据
mat文件生成点注释ground_truth图 - 利用
gaussian_filter函数生成人口密度图
这里我们采用UCF-QNRF的图片作为训练集,如下图所示

ground_truth数据集是由mat文件组成的,数据格式为[y0,x0](不同数据集表示的方法不同)表示人头所在的像素点。利用scipy函数即可读取数据。
加载数据,加载图片和mat文件
gt = scipy.io.loadmat("./UCF-QNRF/Test/img_0001_ann.mat")
img = cv2.imread("./UCF-QNRF/Test/img_0001.jpg")
利用mat文件生成点注释-ground_truth图
k = np.zeros((img.shape[0],img.shape[1]))
for i in range(len(gt)):#生成头部点注释图
if gt[i][0] < img.shape[1] and gt[i][1] < img.shape[0]:
k[int(gt[i][1])][int(gt[i][0])] += gt[i][2]
利用ground_truth图经过高斯滤波
def gaussian_filter_density(gt):
# 初始化密度图
density = np.zeros(gt.shape, dtype=np.float32)
# 获取gt中不为0的元素的个数
gt_count = np.count_nonzero(gt)
# 如果gt全为0,就返回全0的密度图
if gt_count == 0:
return density
sigma = 16
density += scipy.ndimage.filters.gaussian_filter(gt, sigma, mode='constant')
return density
完整代码
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import cm as CM
import cv2
import scipy.ndimage
import scipy.io
def gaussian_filter_density(gt):
# 初始化密度图
density = np.zeros(gt.shape, dtype=np.float32)
# 获取gt中不为0的元素的个数
gt_count = np.count_nonzero(gt)
# 如果gt全为0,就返回全0的密度图
if gt_count == 0:
return density
sigma = 16
density += scipy.ndimage.filters.gaussian_filter(gt, sigma, mode='constant')
return density
def density_map(img,gt):
k = np.zeros((img.shape[0],img.shape[1]))
for i in range(len(gt)):#生成头部点注释图
if gt[i][0] < img.shape[1] and gt[i][1] < img.shape[0]:
k[int(gt[i][1])][int(gt[i][0])] += gt[i][2]
k = gaussian_filter_density(k)
return k
# gt = scipy.io.loadmat("./UCF-QNRF_ECCV18/Test/img_0001_ann.mat")
gt = np.load("teddy\\UCF-Train-Val-Test\\train\\img_0001.npy")
img = cv2.imread("teddy\\UCF-Train-Val-Test\\train\\img_0001.jpg")
groundtruth = density_map(img,gt)
plt.figure(2)
plt.imshow(groundtruth,cmap=CM.jet)
plt.show()
结果
3 代码分析
3.1 🐻dataset和dataload———迭代器设计
在PyTorch中,Dataset是一个非常重要的概念,用于表示数据集的抽象。Dataset对象负责提供数据的索引、数据的获取以及数据的转换(可选)。通过Dataset,我们可以将数据加载到PyTorch中,以便进行模型的训练和评估。
3.1.1 自定义Dataset和dataload的分析
在PyTorch中,通常通过继承torch.utils.data.Dataset类来创建自定义的Dataset。在继承的类中,你需要实现两个主要的方法:
__len__():返回数据集中的样本数。__getitem__(index):根据给定的索引返回数据集中的单个样本。
示例:自定义Dataset
假设我们有一个简单的数据集,其中包含一些图像路径和对应的标签,我们可以这样创建一个自定义的Dataset:
import torch
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import os
class CustomDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
初始化Dataset
:param data_dir: 数据集所在的目录
:param transform: 可选的数据转换操作
"""
self.data_dir = data_dir
self.transform = transform
self.image_paths = [os.path.join(data_dir, img) for img in os.listdir(data_dir) if img.endswith(('.png', '.jpg', '.jpeg'))]
self.labels = [1 if 'cat' in img else 0 for img in self.image_paths] # 假设文件名包含'cat'的是猫,否则是其他
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert('RGB')
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# 使用示例
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((224, 224)),
torchvision.transforms.ToTensor(),
])
dataset = CustomDataset(data_dir='path_to_your_dataset', transform=transform)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
# 现在可以使用dataloader来迭代数据集了
for images, labels in dataloader:
# 进行训练或评估
pass
3.1.2 使用自定义Dataset
在创建了自定义的Dataset后,我们通常会使用DataLoader来封装它。DataLoader提供了批量加载数据、打乱数据、多进程加载等功能,非常适合用于训练深度学习模型。
在上面的示例中,我们已经展示了如何使用DataLoader来加载和迭代数据。DataLoader的参数包括dataset(数据集对象)、batch_size(每个batch的样本数)、shuffle(是否在每个epoch开始时打乱数据)等。
通过自定义Dataset和使用DataLoader,你可以方便地将任何形式的数据集加载到PyTorch中,为深度学习模型的训练和评估提供所需的数据。这是PyTorch处理数据集的核心方法,掌握这一点对于深入使用PyTorch进行深度学习至关重要。
3.1.3 项目dataset分析
两个功能函数,功能委派
def random_crop(im_h, im_w, crop_h, crop_w):
res_h = im_h - crop_h
res_w = im_w - crop_w
i = random.randint(0, res_h)
j = random.randint(0, res_w)
return i, j, crop_h, crop_w
def cal_innner_area(c_left, c_up, c_right, c_down, bbox): # 裁剪区域的左、上、右、下边界。
inner_left = np.maximum(c_left, bbox[:, 0])
inner_up = np.maximum(c_up, bbox[:, 1])
inner_right = np.minimum(c_right, bbox[:, 2])
inner_down = np.minimum(c_down, bbox[:, 3])
inner_area = np.maximum(inner_right-inner_left, 0.0) * np.maximum(inner_down-inner_up, 0.0)
return inner_area # 裁剪区域与每个边界框之间内切区域的面积数组。
这两个函数分别实现了随机裁剪和计算裁剪区域与边界框之间内切区域面积的功能。下面是对这两个函数的详细分析:
random_crop函数:功能:生成一个随机裁剪区域的左上角坐标(i, j)以及裁剪区域的高度(crop_h)和宽度(crop_w)。cal_innner_area函数:功能:计算一个裁剪区域(由c_left, c_up, c_right, c_down定义)与多个边界框(bbox)之间的内切区域面积。
具体类实现
class Crowd(data.Dataset):
def __init__(self, root_path, crop_size,
downsample_ratio, is_gray=False,
method='train'):
self.root_path = root_path
self.im_list = sorted(glob(os.path.join(self.root_path, '*.jpg')))
if method not in ['train', 'val']:
raise Exception("not implement")
self.method = method
self.c_size = crop_size
self.d_ratio = downsample_ratio
assert self.c_size % self.d_ratio == 0
self.dc_size = self.c_size // self.d_ratio
if is_gray:
self.trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
else:
self.trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
def __len__(self):
return len(self.im_list)
def __getitem__(self, item):
img_path = self.im_list[item]
gd_path = img_path.replace('jpg', 'npy')
img = Image.open(img_path).convert('RGB')
if self.method == 'train':
keypoints = np.load(gd_path)
return self.train_transform(img, keypoints)
elif self.method == 'val':
keypoints = np.load(gd_path)
img = self.trans(img)
name = os.path.basename(img_path).split('.')[0]
return img, len(keypoints), name
def train_transform(self, img, keypoints):
-------
return self.trans(img), torch.from_numpy(keypoints.copy()).float(), \
torch.from_numpy(target.copy()).float(), st_size
Crowd实现了两种模式可选的dataset使得train和val可以使用不同的dataset。but why ?
self.dataloaders = {x: DataLoader(self.datasets[x],
collate_fn=(train_collate
if x == 'train' else default_collate),
batch_size=(args.batch_size
if x == 'train' else 1),
shuffle=(True if x == 'train' else False),
num_workers=args.num_workers*self.device_count,
pin_memory=(True if x == 'train' else False))
for x in ['train', 'val']}
datasets[train]每次迭代返回:裁剪后图片,保留的关键点,筛选后的关键点对应的交叉面积比例,以及原始图像的较短边尺寸。
datasets[val]每次迭代返回:原始图片,图片关键点数量和图片名字。
关键点可能由多个维度表示,比如x坐标、y坐标和某种形式的置信度或可见性标志(头的大小范围)。
- 数据划分的目的:
训练集的主要目的是让模型学习数据中的模式和特征。验证集则用于在训练过程中监控模型的性能,以便进行超参数调整、早停(early stopping)等策略来防止过拟合。由于这两个集合的目的不同,因此它们返回的内容也可能不同,以满足各自的需求。 - 评估指标和关注点:
在训练过程中,我们可能更关注模型在训练集上的损失(loss)下降情况,而在验证集上则更关注各种评估指标(如准确率、召回率、F1分数等)的表现。由于这些关注点不同,因此训练集和验证集返回的内容可能也不同,以便分别计算这些指标。 - 数据格式和预处理的标准化:
虽然训练集和验证集的数据格式应该保持一致(例如,都是图像文件或文本文件),但在预处理阶段,它们可能会经历不同的步骤或参数设置。这些预处理步骤可能包括数据归一化、标准化、编码等,以确保模型能够正确处理输入数据。由于训练集和验证集可能使用不同的预处理参数或步骤,因此它们返回的内容也可能不同。
def train_transform(self, img, keypoints):
"""random crop image patch and find people in it"""
wd, ht = img.size
st_size = min(wd, ht)
assert st_size >= self.c_size
assert len(keypoints) > 0
i, j, h, w = random_crop(ht, wd, self.c_size, self.c_size)
img = F.crop(img, i, j, h, w) # 对图片进行随机切片
nearest_dis = np.clip(keypoints[:, 2], 4.0, 128.0)
points_left_up = keypoints[:, :2] - nearest_dis[:, None] / 2.0
points_right_down = keypoints[:, :2] + nearest_dis[:, None] / 2.0
bbox = np.concatenate((points_left_up, points_right_down), axis=1) # 所有关键区域的边界框
inner_area = cal_innner_area(j, i, j+w, i+h, bbox) # 计算随机选中的边界框与所有关键区域的交叉部分面积
origin_area = nearest_dis * nearest_dis # 所有关键区域的面积
ratio = np.clip(1.0 * inner_area / origin_area, 0.0, 1.0)
mask = (ratio >= 0.3)
target = ratio[mask]
keypoints = keypoints[mask]
keypoints = keypoints[:, :2] - [j, i]
if len(keypoints) > 0:
if random.random() > 0.5:
img = F.hflip(img)
keypoints[:, 0] = w - keypoints[:, 0]
else:
if random.random() > 0.5:
img = F.hflip(img)
return self.trans(img), torch.from_numpy(keypoints.copy()).float(), torch.from_numpy(target.copy()).float(), st_size
关键区域可以看作是这个空间被目标身体部分占据。
nearest_dis = np.clip(keypoints[:, 2], 4.0, 128.0)
从keypoints数组中取出所有关键点的第三个维度的值,然后将这些值限制在4.0到128.0的范围内。如果某个关键点的这个值小于4.0,则将其替换为4.0;如果大于128.0,则替换为128.0;
points_left_up = keypoints[:, :2] - nearest_dis[:, None] / 2.0
keypoints[:, :2]是(N, 2)形状,而nearest_dis[:, None] / 2.0是(N, 1)形状,并且NumPy的广播规则允许这种形状的数组进行运算,所以每个关键点的x和y坐标都会减去对应的nearest_dis值的一半。结果是一个形状为(N, 2)的数组,其中包含了调整后的x和y坐标。
points_left_up是一个形状为(N, 2)的NumPy数组,其中N是某个数量(比如关键点的数量),而每行包含两个元素,代表某个“左上”点的x和y坐标。points_right_down是一个形状为(N, 2)的NumPy数组,与points_left_up类似,但每行包含的是对应“右下”点的x和y坐标。
bbox = np.concatenate((points_left_up, points_right_down), axis=1)
由于 points_left_up 和 points_right_down 都是形状为 (N, 2) 的数组,当我们将它们沿着 axis=1 连接时,结果将是一个形状为 (N, 4) 的数组。这个新数组 bbox 的每一行都将包含四个元素:两个来自 points_left_up(左上点的x和y坐标)和两个来自 points_right_down(右下点的x和y坐标)。在计算机视觉的上下文中,这样的 bbox(边界框)通常用于表示图像中某个对象的位置和大小。左上和右下点的坐标定义了该对象在图像中的矩形边界。
这个函数 train_transform 是在训练过程中用于对图像和关键点进行一系列变换的自定义函数,目的是增强模型的泛化能力。该函数主要执行以下步骤:
- 随机裁剪图像:首先,它检查图像的尺寸(宽度和高度),确保它们不小于一个预设的最小裁剪尺寸(
self.c_size)。然后,它使用random_crop函数(该函数未在代码中定义,但我们可以假设它返回一个随机的裁剪区域的位置和大小)来随机选择一个裁剪区域,并对图像进行裁剪。裁剪后的图像将用于后续的处理。 - 处理关键点:对于给定的关键点(通常是人体的关键部位,如眼睛、鼻子、膝盖等),函数首先计算每个关键点到一个“最近距离”的映射(
nearest_dis),这个距离可能是根据关键点周围的某种特征或先验知识来确定的。然后,它使用这个距离来为每个关键点计算一个左上和右下坐标,从而定义一个以关键点为中心的矩形区域(即边界框)。 - 计算交叉面积和比例:函数接着计算裁剪后的图像区域与所有关键点边界框的交叉面积(
inner_area),以及所有关键点边界框的原始面积(origin_area)。然后,它计算交叉面积与原始面积的比例(ratio),并将这个比例用作一个筛选标准,只保留那些交叉面积比例大于或等于0.3的关键点。 - 调整关键点坐标:对于保留下来的关键点,函数调整它们的坐标,以反映它们在裁剪后的图像中的新位置(通过减去裁剪区域的左上角坐标
[j, i])。 - 随机水平翻转:函数以0.5的概率对裁剪后的图像进行水平翻转。如果执行了翻转,则相应地调整关键点的x坐标。
- 返回处理后的数据:最后,函数返回处理后的图像(经过可能的翻转和额外的变换
self.trans)、保留的关键点(转换为PyTorch张量并仅包含x和y坐标)、筛选后的关键点对应的交叉面积比例(也转换为PyTorch张量),以及原始图像的较短边尺寸(st_size)。
这个函数是计算机视觉任务中常见的数据增强方法的一个例子,特别是在处理与人体姿态或关键点检测相关的任务时。通过随机裁剪和翻转图像,以及根据关键点与裁剪区域的相对位置来筛选关键点,该函数有助于模型学习更鲁棒的特征表示。
与dataset想适应的collate设计
def train_collate(batch):
transposed_batch = list(zip(*batch))
# *batch:解包batch,将batch列表中的每个元素作为单独的参数传递给zip函数。
# zip(*batch):zip函数通常用于将多个可迭代对象的元素打包成一个个元组,然后将这些元组解包成一个列表
# batch = [
# (img1, label1, data1),
# (img2, label2, data2),
# (img3, label3, data3),
# # ... 可能还有更多样本
# ]
# transposed_batch = [
# (img1, img2, img3, ...), # 所有图像的列表(或元组)
# (label1, label2, label3, ...), # 所有标签的列表(或元组)
# (data1, data2, data3, ...) # 所有其他数据的列表(或元组)
# ]
# 使用torch.stack沿着新的维度0堆叠这些张量。(N,M)->(numbler_of_samples,N,M)
images = torch.stack(transposed_batch[0], 0)
points = transposed_batch[1] # the number of points is not fixed, keep it as a list of tensor
targets = transposed_batch[2]
st_sizes = torch.FloatTensor(transposed_batch[3])
return images, points, targets, st_sizes
3.2 🐧LOSS函数
self.post_prob = Post_Prob(args.sigma,
args.crop_size,
args.downsample_ratio,
args.background_ratio,
args.use_background,
self.device)
self.criterion = Bay_Loss(args.use_background, self.device)
3.2.1 Post_Prob
后验概率(Posterior Probability)
class Post_Prob(Module):
def __init__(self, sigma, c_size, stride, background_ratio, use_background, device):
super(Post_Prob, self).__init__()
assert c_size % stride == 0
self.sigma = sigma
self.bg_ratio = background_ratio
self.device = device
# coordinate is same to image space, set to constant since crop size is same
self.cood = torch.arange(0, c_size, step=stride,
dtype=torch.float32, device=device) + stride / 2
self.cood.unsqueeze_(0)
self.softmax = torch.nn.Softmax(dim=0)
self.use_bg = use_background
def forward(self, points, st_sizes):
num_points_per_image = [len(points_per_image) for points_per_image in points]
# points = [
# [point1_image1, point2_image1, ...], # 第一个图像的点列表
# [point1_image2, point2_image2, ...], # 第二个图像的点列表
# ... ]
# 计算每图像的点数,并存到num_points_per_image中。
all_points = torch.cat(points, dim=0)
if len(all_points) > 0:
x = all_points[:, 0].unsqueeze_(1) # 提取第一列后再增加一个维度 (N, 1)
y = all_points[:, 1].unsqueeze_(1) # 提取第二列后再增加一个维度 (N, 1)
x_dis = -2 * torch.matmul(x, self.cood) + x * x + self.cood * self.cood
y_dis = -2 * torch.matmul(y, self.cood) + y * y + self.cood * self.cood
y_dis.unsqueeze_(2)
x_dis.unsqueeze_(1)
dis = y_dis + x_dis
dis = dis.view((dis.size(0), -1))
dis_list = torch.split(dis, num_points_per_image)
prob_list = []
for dis, st_size in zip(dis_list, st_sizes):
if len(dis) > 0:
if self.use_bg:
min_dis = torch.clamp(torch.min(dis, dim=0, keepdim=True)[0], min=0.0)
bg_dis = (st_size * self.bg_ratio) ** 2 / (min_dis + 1e-5)
dis = torch.cat([dis, bg_dis], 0) # concatenate background distance to the last
dis = -dis / (2.0 * self.sigma ** 2)
prob = self.softmax(dis)
else:
prob = None
prob_list.append(prob)
else:
prob_list = []
for _ in range(len(points)):
prob_list.append(None)
return prob_lis
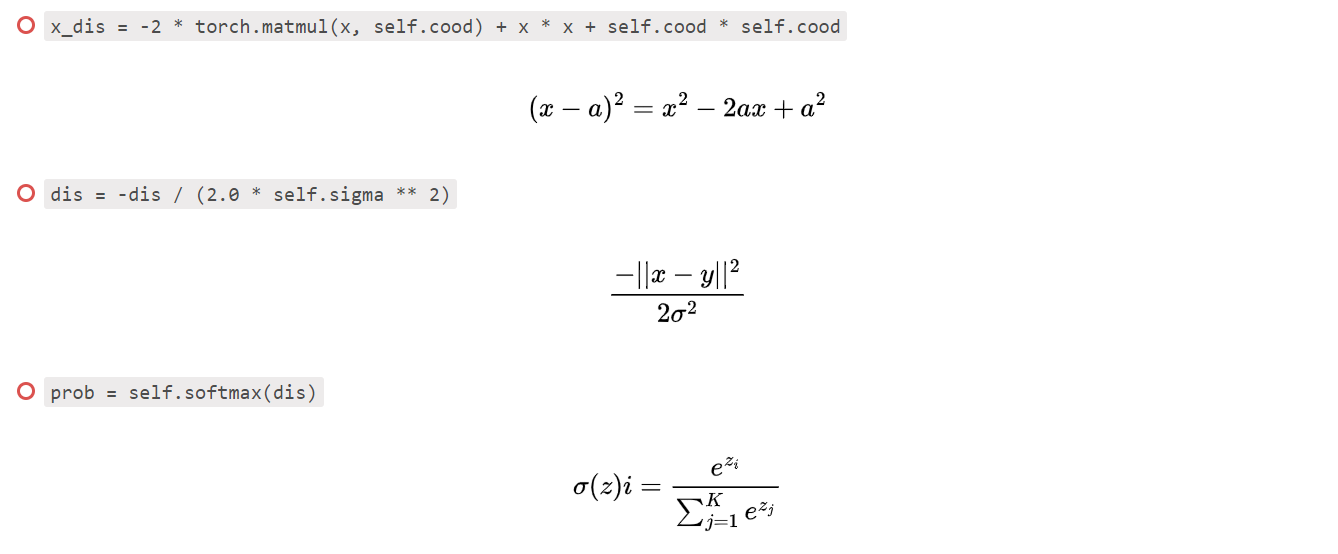
这段代码定义了一个名为Post_Prob的类,该类继承自PyTorch的Module类,用于执行后处理操作,特别是在处理与图像中点相关的任务时,如目标检测或关键点检测等。这个类的主要目的是根据给定的点(可能是检测到的目标或关键点)和一系列参数,计算这些点相对于某个固定网格(或坐标系统)的概率分布。下面是对这个类及其方法的详细分析:
前向传播函数 forward
参数
points:一个列表,包含每个图像中检测到的点的坐标(二维,每行一个点)。
st_sizes:一个列表,包含每个图像的标准尺寸(或特征尺寸),可能用于计算背景距离。
操作
- 首先,计算每个图像中点的数量,并存储在
num_points_per_image中。 - 将所有图像的点合并到一个单一的张量
all_points中,方便后续批量处理。 - 提取
all_points中的x和y坐标,并分别增加一个维度以匹配矩阵乘法的要求。 - 计算每个点与坐标网格上每个点之间的平方距离(
x_dis和y_dis),然后相加得到总距离dis。 - 将
dis张量重新整形,并根据每个图像中点的数量分割成dis_list,以便对每个图像分别处理。 - 对于
dis_list中的每个dis和对应的st_size,计算该图像中每个点相对于坐标网格的概率分布(虽然代码中并未直接计算概率,而是计算了距离,但基于这些距离可以进一步计算高斯概率)。 - 如果启用了背景点(
self.use_bg为真),则计算背景点的“距离”,这里的“距离”实际上是基于最小距离和背景比率计算的一个值,用于在概率分布中考虑背景区域。
- 首先,计算每个图像中点的数量,并存储在
3.2.2 Bay_Loss
贝叶斯概率
class Bay_Loss(Module):
def __init__(self, use_background, device):
super(Bay_Loss, self).__init__()
self.device = device
self.use_bg = use_background
def forward(self, prob_list, target_list, pre_density):
loss = 0
for idx, prob in enumerate(prob_list): # iterative through each sample
if prob is None: # image contains no annotation points
pre_count = torch.sum(pre_density[idx])
target = torch.zeros((1,), dtype=torch.float32, device=self.device)
else:
N = len(prob)
if self.use_bg:
target = torch.zeros((N,), dtype=torch.float32, device=self.device)
target[:-1] = target_list[idx]
else:
target = target_list[idx]
pre_count = torch.sum(pre_density[idx].view((1, -1)) * prob, dim=1) # flatten into vector
loss += torch.sum(torch.abs(target - pre_count))
loss = loss / len(prob_list)
return loss
3.3 🕊️模型网络设计和训练过程
3.3.1 vgg模型简介
self.model =vgg19()
VGG19模型是一个深度卷积神经网络(CNN),由牛津大学的Visual Geometry Group(VGG)研究团队开发并命名。该模型在多个方面展现出了其重要的作用和优势,具体如下:
- 图像处理与分类
- 图像分类:VGG19在2014年的ImageNet图像识别挑战赛中取得了非常优秀的成绩,证明了其在图像分类任务中的强大能力。它能够通过学习图像中的特征,将图像准确地分类到不同的类别中。
- 特征提取:VGG19的每一层都可以看作是一个独立的特征提取器,专注于从输入数据中提取局部特征。这些特征经过一系列的非线性变换和组合,最终形成完整的图像表示,这对于图像处理和计算机视觉任务至关重要。
- 2. 结构特点与优势
- 网络深度:VGG19的名称中的“19”代表着其网络的总层数(包括卷积层和全连接层),这使得它成为当时相对较深的神经网络之一。深度网络有助于模型学习到更复杂的特征表示,从而提高模型的性能。
- 卷积核与池化层:VGG19使用了多个连续的小型卷积核(如3x3)来替代单一的大型卷积核。这种设计不仅增加了网络对不同尺度特征的捕捉能力,还提高了模型的泛化性能。同时,每两个卷积层之间都插入了一个池化层(如2x2的池化核),有助于减少特征图的尺寸和计算量。
- 3 迁移学习与预训练模型
- 预训练模型:VGG19有一个预训练的版本,这意味着可以直接使用在大量图像数据上训练好的模型参数,而不需要从头开始训练。这大大节省了训练时间,并使得VGG19能够在数据较少的任务中表现出色。
- 迁移学习:迁移学习是一种将在一个任务上训练好的模型应用到另一个相关任务上的方法。VGG19的预训练模型可以作为新任务的起点,通过在新数据上进行微调来适应新的任务需求。
- 4 应用领域
- 图像识别:VGG19广泛应用于自然图像识别领域,包括但不限于动物、植物、车辆等物体的识别。
- 物体检测:在物体检测任务中,VGG19可以作为特征提取器,与检测算法相结合来定位图像中的物体。
- 语义分割:在语义分割任务中,VGG19可以帮助模型理解图像中每个像素的类别信息,从而实现精细的图像分割。
5 后续影响与改进
- 后续研究:VGG19的成功启发了后续研究者使用更深、更复杂的网络架构来解决计算机视觉领域的问题。许多改进和变种都是基于VGG19的结构进行的。
- 优化策略:为了解决VGG19参数量较大、计算复杂度较高等问题,研究者们提出了许多优化策略,如知识蒸馏、轻量级网络结构设计等,以提高模型效率和性能。
综上所述,VGG19模型在图像处理与分类、特征提取、迁移学习与预训练模型以及多个应用领域中都发挥着重要作用。其独特的网络结构和强大的特征提取能力使得它成为计算机视觉领域中的经典模型之一。
4 实验结果记录
python preprocess_dataset.py --origin-dir ../tmp/UCF-QNRF_ECCV18 --data-dir ../teddy/UCF-Train-Val-Test
python train.py --data-dir ../teddy/UCF-Train-Val-Test --save-dir ../teddy/vgg
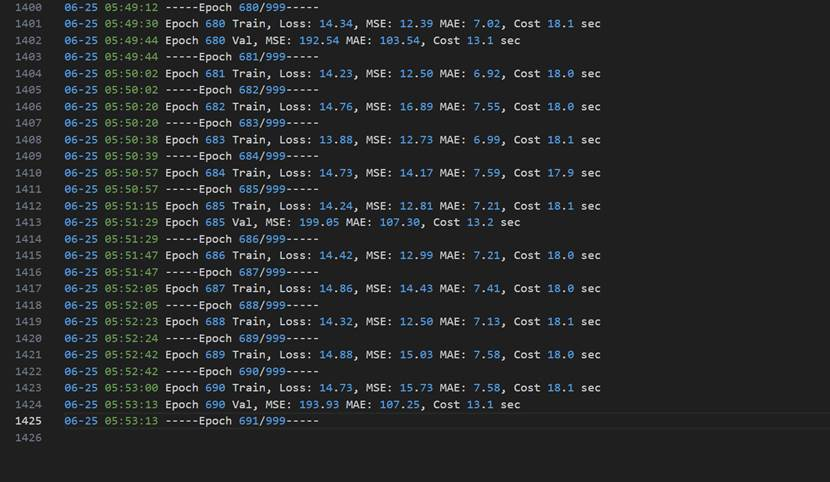
后面大概是服务器欠费自动截止训练了,考虑到已经得到比原模型好的结果就没有进行2次训练。
python test.py --data-dir ../teddy/UCF-Train-Val-Test --save-dir ../teddy/vgg
结果可视化
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as CM
import os
npy_folder = './npyfile'
image_folder = './image'
if not os.path.exists(image_folder):
os.makedirs(image_folder)
for npy_file in os.listdir(npy_folder):
if npy_file.endswith('.npy'):
dm = np.load(os.path.join(npy_folder, npy_file))
# Normalize the input data
dm_normalized = dm / np.max(dm)
fig, ax = plt.subplots()
ax.imshow(dm_normalized[0, 0], cmap=CM.jet, vmin=0, vmax=1) # Adjust indexing as needed
name = os.path.splitext(npy_file)[0]
plt.savefig(os.path.join(image_folder, '{}.png'.format(name)))
test/img_0001.jpg测试

代码段一:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as CM
import os
npy_path = "teddy\\UCF-Train-Val-Test\\npyfile"
images_path = "teddy\\UCF-Train-Val-Test\\test"
npy_file = "img_0001.npy"
data_pre = np.load(os.path.join(npy_path, npy_file))
print("data_pre[0,0] :",data_pre[0,0])
print("data_pre.shape :",data_pre.shape)
print(np.sum(data_pre))
# Normalize the input data
data_pre_normalized = data_pre / np.max(data_pre)
print("-"*50)
data_test = np.load(os.path.join(images_path, npy_file))
print("data_test :",data_test)
print("data_test.shape :",data_test.shape)
输出:
data_pre[0,0] : [[5.2732881e-05 4.4326764e-05 1.9371044e-05 ... 1.0430161e-04
2.6183669e-05 3.2673590e-05]
[2.0994106e-04 4.2500580e-04 3.4432928e-03 ... 3.9682258e-05
1.7801765e-05 1.7811265e-04]
[5.6461222e-03 4.3547332e-02 3.5645209e-02 ... 6.0658390e-04
4.1515566e-05 9.3833078e-05]
...
[1.4514025e-02 4.7545478e-02 4.9227014e-02 ... 1.6733538e-05
1.7937738e-05 7.8277662e-06]
[5.9578894e-04 2.3728251e-03 6.3006370e-03 ... 1.6372651e-05
1.4228746e-05 1.0157935e-05]
[8.0659054e-05 9.9725090e-05 5.7616737e-05 ... 1.7749611e-05
1.6583595e-05 1.2622215e-05]]
data_pre.shape : (1, 1, 234, 312)
1203.4796
-----------------------------------------------------------------------
data_test : [[ 445.19424 1790.518 ]
[ 474.8705 1739.259 ]
[ 512.64026 1820.1942 ]
...
[ 972.7157 1494.6793 ]
[1933.0287 181.25717]
[1572.6423 134.19641]]
data_test.shape : (975, 2)
代码段二:
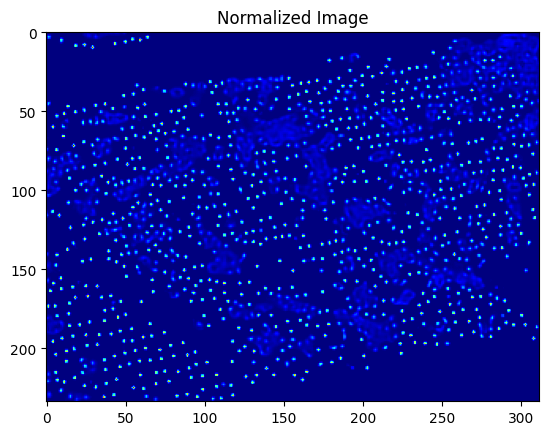
fig, ax = plt.subplots()
ax.imshow(data_pre_normalized[0, 0], cmap=CM.jet, vmin=0, vmax=1) # Adjust indexing as needed
ax.set_title('Normalized Image')
plt.show()
输出
代码段三:
from matplotlib import pyplot as plt
from matplotlib import cm as CM
import cv2
import scipy.ndimage
import scipy.io
def gaussian_filter_density(gt):
# 初始化密度图
density = np.zeros(gt.shape, dtype=np.float32)
# 获取gt中不为0的元素的个数
gt_count = np.count_nonzero(gt)
# 如果gt全为0,就返回全0的密度图
if gt_count == 0:
return density
sigma = 16
density += scipy.ndimage.filters.gaussian_filter(gt, sigma, mode='constant')
return density
def density_map(img,gt):
k = np.zeros((img.shape[0],img.shape[1]))
for i in range(len(gt)):#生成头部点注释图
if gt[i][0] < img.shape[1] and gt[i][1] < img.shape[0]:
k[int(gt[i][1])][int(gt[i][0])] += 1
k = gaussian_filter_density(k)
return k
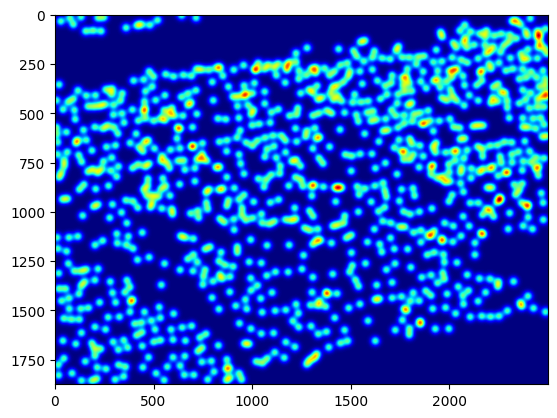
gt = data_test
image = os.path.splitext(npy_file)[0] + '.jpg'
img = cv2.imread(os.path.join(images_path,image))
groundtruth = density_map(img,gt)
plt.figure(2)
plt.imshow(groundtruth,cmap=CM.jet)
plt.show()
输出:
代码段四:
import numpy as np
from PIL import Image
data = data_pre[0,0]
# 读取.jpg文件,获取其大小
image = Image.open(image_path)
image_size = image.size
# 调整.npy文件的大小以匹配.jpg文件的大小
data_resized = np.array(Image.fromarray(data).resize(image_size))
# 创建一个新的可视化图像
fig, ax = plt.subplots()
ax.imshow(data_resized, cmap='gray') # 根据需要选择合适的色彩映射
# 将.jpg图像叠加在.npy数据上
ax.imshow(image, alpha=0.5) # 调整alpha值控制图像重叠的透明度
plt.axis('off') # 关闭坐标轴
plt.show()
输出:

可以看到训练输出结果和原本的数据基本一致
训练输出结果采用图存储模式即:(234, 312)
原始数据结果采用点存储模式即:(975, 2)